Write event messages into Azure Data Lake Storage Gen2 with Apache Flink® DataStream API
Important
This feature is currently in preview. The Supplemental Terms of Use for Microsoft Azure Previews include more legal terms that apply to Azure features that are in beta, in preview, or otherwise not yet released into general availability. For information about this specific preview, see Azure HDInsight on AKS preview information. For questions or feature suggestions, please submit a request on AskHDInsight with the details and follow us for more updates on Azure HDInsight Community.
Apache Flink uses file systems to consume and persistently store data, both for the results of applications and for fault tolerance and recovery. In this article, learn how to write event messages into Azure Data Lake Storage Gen2 with DataStream API.
Prerequisites
- Apache Flink cluster on HDInsight on AKS
- Apache Kafka cluster on HDInsight
- You're required to ensure the network settings taken care as described on Using Apache Kafka on HDInsight. Make sure HDInsight on AKS and HDInsight clusters are in the same Virtual Network.
- Use MSI to access ADLS Gen2
- IntelliJ for development on an Azure VM in HDInsight on AKS Virtual Network
Apache Flink FileSystem connector
This filesystem connector provides the same guarantees for both BATCH and STREAMING and is designed to provide exactly once semantics for STREAMING execution. For more information, see Flink DataStream Filesystem.
Apache Kafka Connector
Flink provides an Apache Kafka connector for reading data from and writing data to Kafka topics with exactly once guarantees. For more information, see Apache Kafka Connector.
Build the project for Apache Flink
pom.xml on IntelliJ IDEA
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Program for ADLS Gen2 Sink
abfsGen2.java
Note
Replace Apache Kafka on HDInsight cluster bootStrapServers with your own brokers for Kafka 3.2
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class KafkaSinkToGen2 {
public static void main(String[] args) throws Exception {
// 1. get stream execution env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration flinkConfig = new Configuration();
flinkConfig.setString("classloader.resolve-order", "parent-first");
env.getConfig().setGlobalJobParameters(flinkConfig);
// 2. read kafka message as stream input, update your broker ip's
String brokers = "<update-broker-ip>:9092,<update-broker-ip>:9092,<update-broker-ip>:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
stream.print();
// 3. sink to gen2, update container name and storage path
String outputPath = "abfs://<container-name>@<storage-path>.dfs.core.windows.net/flink/data/click_events";
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(2))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute("Kafka Sink To Gen2");
}
}
Package jar, and submit to Apache Flink.
Upload the jar to ABFS.

Pass the job jar information in
AppModecluster creation.
Note
Make sure to add classloader.resolve-order as ‘parent-first’ and hadoop.classpath.enable as
trueSelect Job Log aggregation to push job logs to storage account.

You can see the job running.





Validate streaming data on ADLS Gen2
We're seeing the click_events streaming into ADLS Gen2.

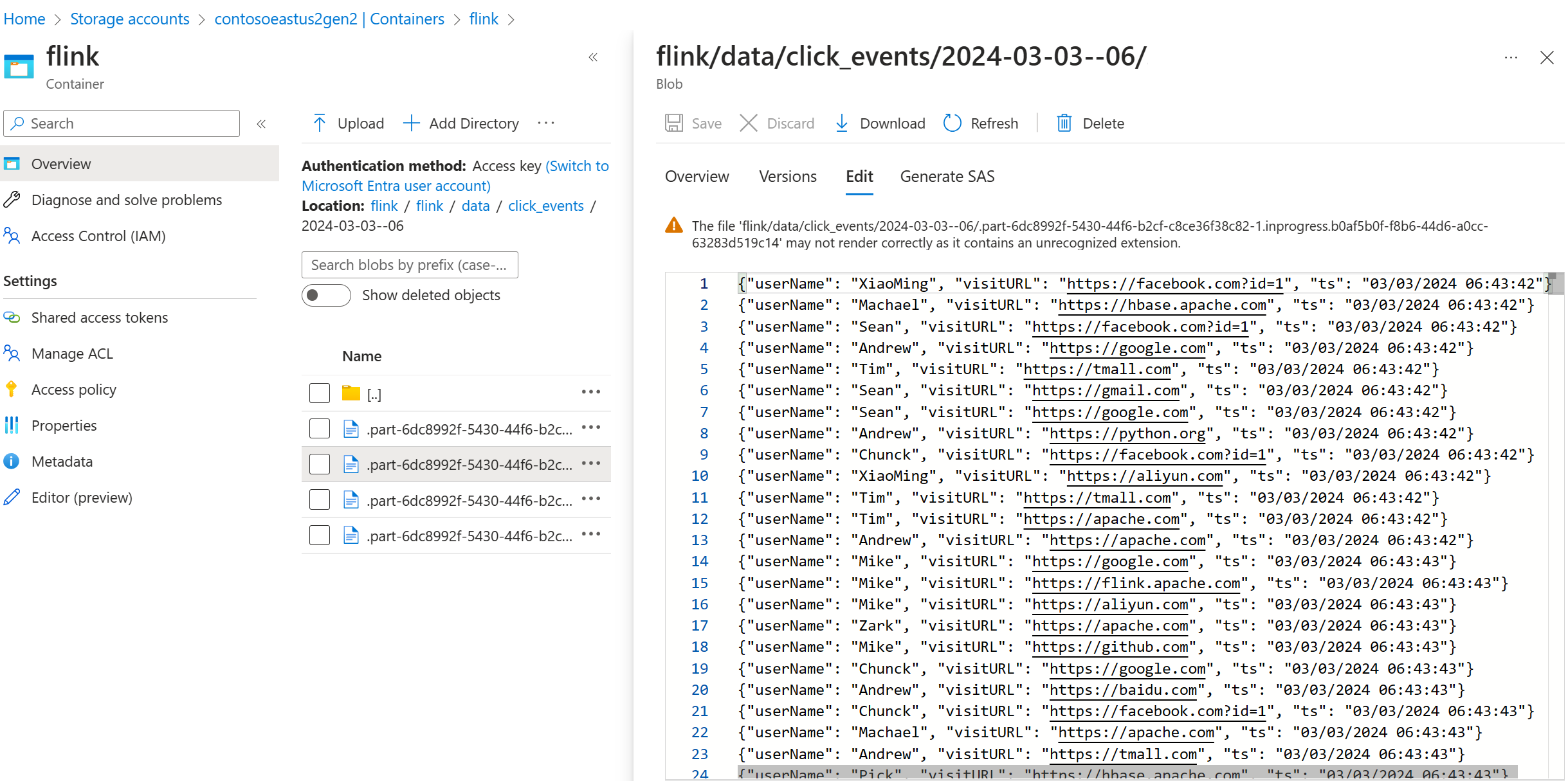
You can specify a rolling policy that rolls the in-progress part file on any of the following three conditions:
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(5))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
Reference
- Apache Kafka Connector
- Flink DataStream Filesystem
- Apache Flink Website
- Apache, Apache Kafka, Kafka, Apache Flink, Flink, and associated open source project names are trademarks of the Apache Software Foundation (ASF).
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for